What is Reliability Engineering?
Reliability engineering is the practice of designing and maintaining equipment to ensure it performs exactly as it should, for as long as it needs to, without failing. It uses data and smart maintenance strategies to keep your assets running safely and efficiently, while significantly reducing unexpected breakdowns and long-term repair costs.
Reliability Concepts: The Foundation of Industrial Uptime
In the context of the rapidly modernizing industrial sector in India, “reliability” is often misunderstood as merely “not breaking down.” For the astute plant head, reliability is a measurable probability. To master it, one must distinguish between the three pillars of maintenance performance:
- Reliability : The probability that an asset will perform its intended function without failure for a specific duration.
- Availability : The percentage of time a system is functional and ready for production, accounting for both scheduled and unscheduled maintenance.
- Maintainability : The ease and speed with which an asset can be restored to a functional state after a failure occurs.
The Failure Reality: The Indian Context
Consider “Company Alpha,” a chemical processing facility in Gujarat. For years, the team operated in a reactive cycle. Vibration issues in their centrifugal pumps were ignored until catastrophic failure occurred. They suffered from the “Maintenance Death Spiral”. Fixing one failure caused another, leading to increased parts consumption and erratic production schedules.
Most industrial failures in India – especially those subject to high ambient temperatures, humidity, and fluctuating power grids, follow specific patterns. While the classic “Bathtub Curve” (mortality, random failure, wear-out phase) is the theoretical baseline, modern reliability engineering acknowledges that most failures are age-independent (random). They are driven by stressors rather than just time-in-service.
Lifecycle Thinking
True reliability engineering shifts the focus from “repairing machines” to “managing assets.” It requires a cradle-to-grave mindset where design choices, installation standards, and operating procedures (SOPs) are integrated to maximize the Mean Time Between Failures (MTBF).
RCM Approach: Moving from Reactive to Proactive
The cornerstone of modern reliability engineering in India is Reliability-Centered Maintenance (RCM). RCM is not a one-size-fits-all checklist, it is a structured framework (defined by the SAE JA1011 standard) used to determine the most effective maintenance tasks for any physical asset.
The RCM Framework
When Unit Alpha required intervention, ordering new parts wasn’t the first task on the list. Seven critical questions were first asked :
- Functions: What is the item supposed to do? (e.g., maintain pressure at 5 bar).
- Functional Failures: How can it fail? (e.g., loss of pressure).
- Failure Modes: What causes each functional failure? (e.g., seal degradation).
- Failure Effects: What happens when it fails? (e.g., production stop).
- Failure Consequences: Does it impact safety or environment? (e.g., hazardous leak).
- Proactive Tasks: Is there a predictive or preventive task that works?
- Default Actions: If no task works, what is the redesign requirement?
From Reactive to Predictive
By mapping Failure Modes and Effects Analysis (FMEA), Unit Alpha stopped performing unnecessary “time-based” overhauls. They realized that opening a gearbox every 6 months to “check it” was actually introducing contamination, a leading cause of premature failure in industrial India. RCM allowed them to shift from “maintenance by calendar” to “maintenance by condition.”
Tools & Technologies: The Engine of Reliability
Reliability engineering in industry is data-driven. Without diagnostics, you are guessing. At Hofincons, we deploy a stack of technologies that provide visibility into the P-F Interval -the time between the first potential sign of failure (P) and the functional failure (F).
Core Diagnostic Stack
- Vibration Analysis: The gold standard for rotating equipment. By analyzing frequency spectrums, we identify bearing defects, misalignment, or unbalance long before they cause a shutdown.
- Thermography: Essential in the Indian climate to prevent electrical failures and track motor thermal loading.
- Ultrasound Testing: Critical for detecting leaks in compressed air systems and early-stage bearing fatigue in slow-speed equipment.
- Oil Analysis: Acting as a “blood test” for machinery, providing early warning of internal wear and contaminant ingress.
The Impact
By integrating these sensors into a centralized CMMS (Computerized Maintenance Management System) or EAM (Enterprise Asset Management) platform, we provide maintenance teams with a “control tower” view of the plant.
Result: In a recent deployment of these technologies, we observed that equipment failures reduced by 30% within the first 12 months.
Before vs. After Scenario:
- Before: The maintenance team waited for vibration alarms to trigger a shutdown, resulting in emergency procurement and high-cost “expedited” labor.
- After: Vibration signatures identified a bearing defect 45 days before failure. Maintenance was scheduled during a planned production lull, requiring only a $200 bearing replacement rather than a $20,000 motor rewind and 48 hours of downtime.
Business Impact: Quantifying Reliability
Reliability engineering is often viewed as a cost center, but in competitive markets, it is a significant profit driver. The business case for asset reliability optimization is built on four pillars:
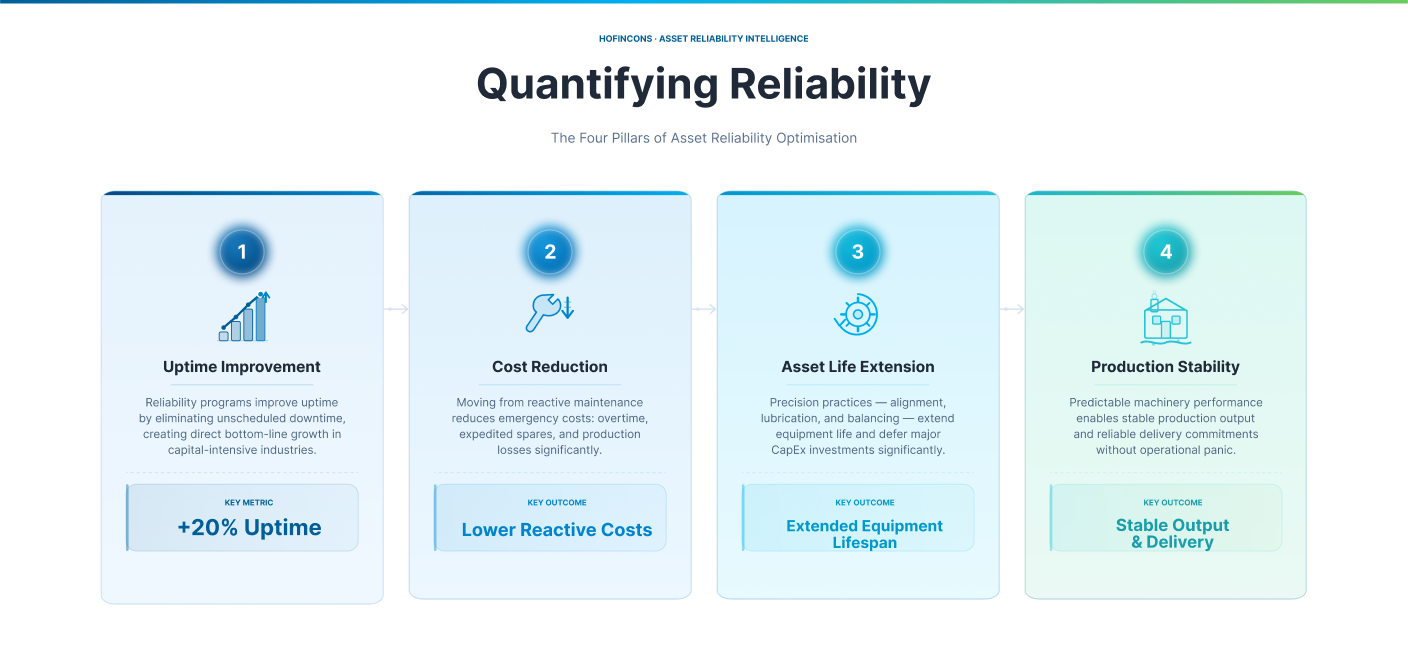
- Uptime Improvement
Reliability programs improve uptime by 20% by eliminating unscheduled downtime. In capital-intensive industries, this creates direct bottom-line growth. - Cost Reduction
By shifting away from reactive maintenance, organizations see a significant drop in “emergency” costs (overtime labor, air-freighted spares, and lost production). - Asset Life Extension
Precision maintenance – alignment, lubrication, and balance can double the life of rotating assets, deferring massive capital expenditure (CapEx) for equipment replacement. - Production Stability
Predictable machinery leads to predictable output. For plant heads, this means meeting delivery commitments to OEMs or end-customers without the “panic mode” that plagues under-performing facilities.
The Resolution at Unit Alpha: Within 18 months, the facility moved from a reactive firefighting mode to a controlled, predictive environment. Maintenance costs decreased by 15%, while total throughput increased by 12% due to consistent machine availability. The plant was no longer chasing failures; they were managing performance.
How Hofincons Improves Reliability
Hofincons provides the specialized expertise required to navigate the complexity of industrial maintenance. We don’t just provide labor; we provide a reliable partnership.
Our approach includes:
- Comprehensive Reliability Assessments: We benchmark your current maintenance maturity against global standards and identify the “low hanging fruit” for immediate improvement.
- RCM Implementation: Our reliability engineers facilitate FMEA workshops and develop dynamic maintenance strategies tailored to your specific operating context.
- Maintenance Optimization Programs: We audit your CMMS/EAM usage, ensuring that data quality supports decision-making rather than cluttering it.
- Continuous Improvement Frameworks: We institutionalize a culture of reliability, ensuring that operators and maintainers are aligned on proactive monitoring.
Whether you are looking to audit your existing strategy or build a predictive maintenance program from the ground up, Hofincons bridge the gap between engineering theory and industrial reality.
Explore our full suite of asset management solutions.